



Uncertainty Quantification for Flow-Based Vision-Language-Action Models
flow matching 기반 VLA의 action generation ODE에서 ensemble velocity field disagreement(VFD)를 측정해 epistemic uncertainty를 추정하고, 이를 failure detection과 SAVE active fine-tuning data acquisition에 사용해 expert demonstration sample efficiency를 높임
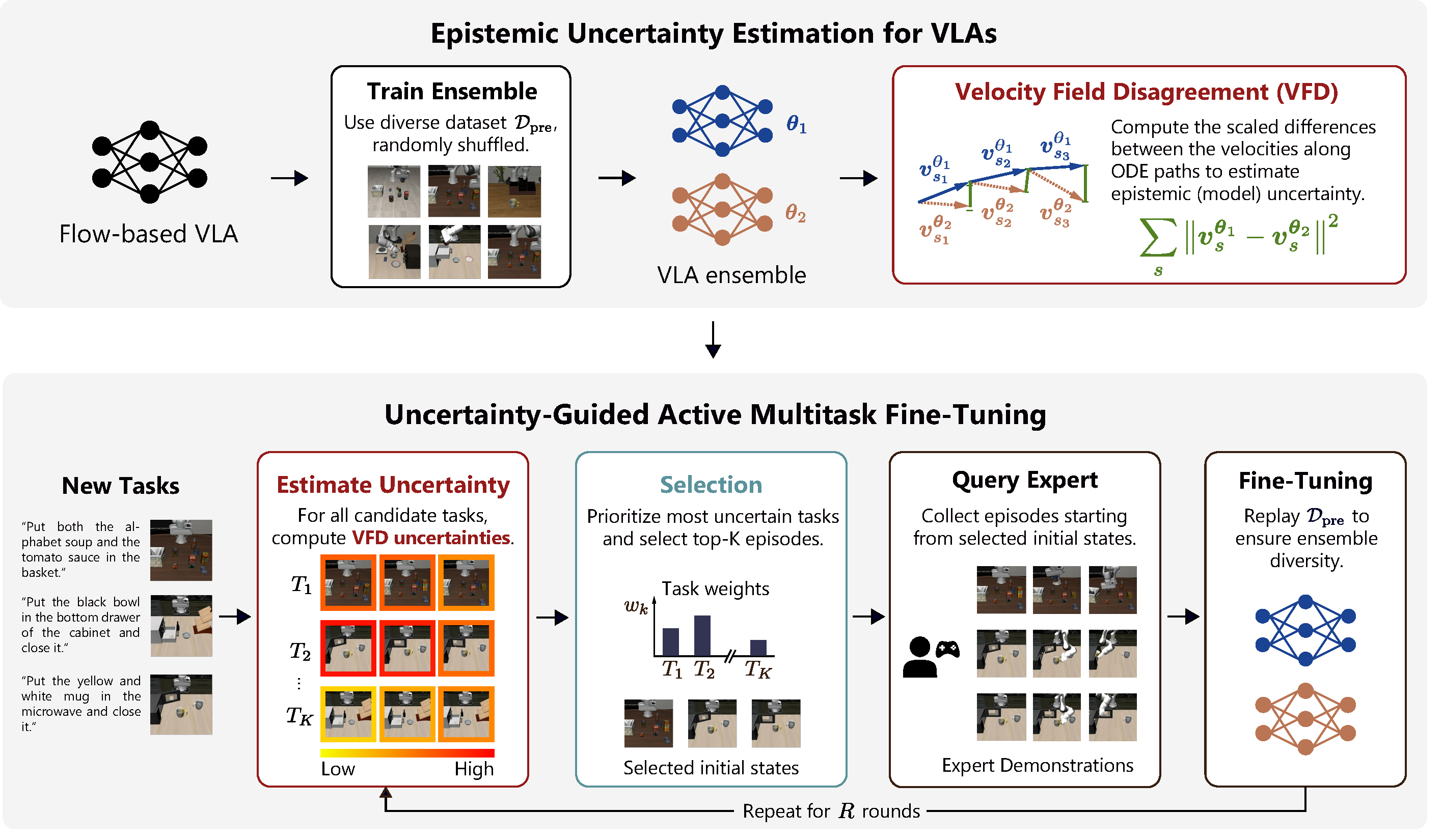
Overview Figure
Summary
- 기존 flow-based VLA는 pretrained vision-language backbone과 flow matching action head로 강력한 manipulation 성능을 보이지만, predicted action의 confidence나 failure 가능성을 직접 quantify하지 못한다.
- 이 논문은 non-stationary deployment 환경에서 VLA가 pretraining distribution 밖의 task/object/scene을 만나도 “모른다”는 신호를 내지 못하고 실패할 수 있다는 문제를 다룬다.
- 핵심 아이디어는 작은 VLA ensemble의 flow-matching velocity field가 ODE sampling path를 따라 얼마나 disagree하는지 측정하면 epistemic uncertainty를 근사할 수 있다는 것이다.
- 이를 위해 저자들은 Velocity Field Disagreement(VFD)를 수학적으로 유도하고, VFD uncertainty를 task-level 및 initial-state-level acquisition score로 사용하는 SAVE(active multitask fine-tuning framework)를 제안한다.
- LIBERO benchmark에서 VFD는 calibration, failure detection, active fine-tuning sample efficiency에서 baseline보다 우수하며, SAVE는 uncertainty-guided data acquisition으로 baseline 대비 최소 22% 적은 expert demonstration으로 유사 성능에 도달한다.