



UniviewVLA: A Unified Multiview Vision-Language-Action Model with World Modeling
agent-view와 wrist-view의 두 프레임만으로 candidate auxiliary-views의 다음 장면 token을 생성하고, motion-relevant token 16개로 압축한 뒤 action entropy가 가장 낮은 view를 선택해 FAST action token을 생성하는 autoregressive multiview VLA
Overview Figure
Summary
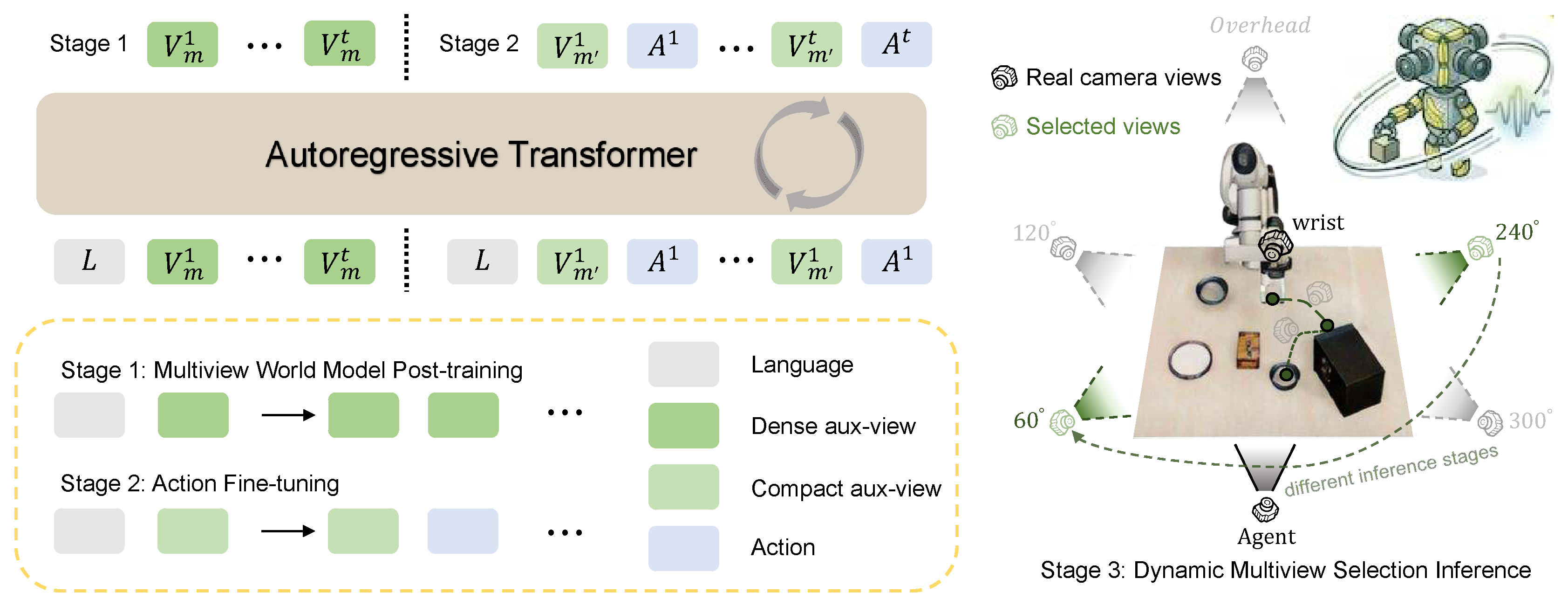
- 기존 multiview manipulation은 추가 physical camera를 배치해 training–inference camera configuration을 맞추거나 explicit 3D reconstruction을 수행해야 하며, 두 방식 모두 deployment cost와 scalability 문제가 있다.
- 이 논문은 standard agent-view와 wrist-view만 사용하면서도 occluded action-critical cue와 미래 scene evolution을 policy에 제공하는 것을 목표로 한다.
- 핵심 아이디어는 pretrained autoregressive UniVLA를 auxiliary workspace view의 next-frame VQ token을 예측하도록 post-train하고, 이후 future auxiliary view token과 FAST action token을 한 sequence로 생성하게 만드는 것이다.
- Dense auxiliary view의 625개 token 중 consecutive-frame VQ embedding 변화가 큰 16개만 학습 대상으로 사용하고, inference에서는 각 후보 시점으로부터 얻은 action-token entropy를 비교해 가장 낮은 시점을 30 timestep마다 선택한다.
- LIBERO 95.8%, CALVIN ABCD→D 4.60을 기록했으며, 별도 occlusion simulation task에서는 40.0%에서 73.3%, 두 real-robot task 평균에서는 33.4 percentage point 향상을 보였다.
Further Analysis
- deploy 시 카메라를 없앤 것이지, 학습 시 multiview camera supervision을 없앤 것은 아니다
- Standard simulation benchmark에서는 demonstration을 추가 workspace camera로 replay하고, real-robot에서도 별도의 side-view camera로 100개 demonstration/task를 수집한다.
- 생성된 view는 새로운 sensor observation이 아니라 학습된 scene prior를 이용한 visual completion이다
- 두 입력 시점에서 완전히 보이지 않는 hidden state는 원칙적으로 식별할 수 없으므로, 모델은 해당 정보를 복원한다기보다 추정하거나 hallucinate한다.
- 이 모델의 “world model”은 $p(o_{t+1}^{v}\mid o_{t-1:t},L)$을 학습하지만, $p(o_{t+1}\mid o_t,a_t)$ 을 학습하지 않는다
- 따라서 candidate action을 rollout하거나 MPC에 사용하는 forward dynamics model은 아니다.
- Motion-Informative Token Compression은 auxiliary token 수를 view당 625개에서 16개로 줄이지만, “움직이는 영역”과 “행동 결정에 중요한 영역”이 항상 같은 것은 아니다
- 움직이지 않는 goal object, contact target, switch state는 top-$K$ motion token에서 빠질 수 있다.
- Action entropy가 낮다는 것과 행동이 맞다는 것은 동일하지 않다
- 모델이 잘못된 미래 시점을 자신 있게 생성하면 entropy는 낮으면서 action은 틀릴 수 있다.
- 이 모델은 occlusion robustness를 inference latency와 맞바꾼다
- autoregressive VQ+FAST token stream + 5-view entropy selection 구조는 flow/diffusion policy 대비 control frequency가 낮을 수밖에 없고, 논문이 강조하는 ‘closed-loop efficient’는 latency 절대값이 아니라 full-view(6~7s) 대비 상대적 개선이라는 점을 구분해야 한다.